









































Go List
 2025-01-17
2025-01-17白皮書下載 | 英飛凌高信噪比 MEMS 麥克風驅動人工智慧交互
來源: 英飛凌官方微信
本文作者:作者 Gunar Lorenz 博士 / 英飛凌科技公司 技術市場高級總監
& 校對 丁越/英飛凌消費、計算與通訊業務大中華區 首席工程師

導言
在英飛凌,我們一直堅信卓越的音訊解決方案對於提升消費類設備的使用者體驗至關重要。我們堅定不移地致力於創新,在主動降噪、語音透傳、錄音室錄音、音訊變焦和其他相關技術方面取得了顯著進步,對此我們深感自豪。作為 MEMS 麥克風的領先供應商,英飛凌集中資源改善 MEMS 麥克風的音訊品質,為 TWS 和耳罩式耳機、筆記型電腦、平板電腦、會議系統、智慧手機、智慧音箱、助聽器甚至汽車等各種消費設備帶來卓越體驗。
今天,我們生活在一個激動人心的時代,人工智慧正在徹底改變日常生活,而 ChatGPT 等工具正在通過直觀的文本和語音交互重新定義工作效率。隨著人工智慧系統的不斷進步,傳統的商業模式、信仰和假設正在受到挑戰。語音在新興的人工智慧生態系統中扮演什麼角色?作為企業領導者,我們是否需要重新思考我們的信念?生成式人工智慧的興起是否會降低高品質語音輸入的重要性,或者高品質語音輸入是否會成為廣泛採用人工智慧服務和個人助理的必要條件?
人工智慧,從得力助手到最好的朋友
人類不僅會根據問題的內容,也會根據提問的形式調整自己的回答,這是很自然的事情。人類的聲音提供了各種線索,可用來判斷提問者的年齡、性別、社會和文化背景以及情緒狀態。此外,識別所處的環境(如機場、辦公室、交通或跑步等體育活動)也有助於確定提問者的意圖,並相應地調整答案並更好的對話。
儘管人工智慧的能力有了長足的進步,但人們仍然認為,基於人工智慧的輔助工具缺乏正確預測人類提問意圖或特定資訊將如何被解讀的能力。為了改善人機交互,人工智慧在做出修辭選擇時應考慮三個關鍵因素:對聽者的瞭解、聽者的情緒狀態和環境背景。
在許多情況下,僅憑接收到的音訊信號就足以提取有用的資訊並做出適當的反應。例如,考慮一下與素未謀面的人進行電話或音訊會議的情況。更重要的是,考慮一下在沒有機會當面交流的情況下,一個人在反復交談後對另一個人的感知是如何發展和變化的。
最近的研究表明,即使人工智慧的語言反應風格發生微小的變化,也會導致人工智慧的社交能力和個性發生明顯變化。我們有理由假設,在適當的聲音輸入水準下,未來的人工智慧系統將能夠作為有效的夥伴發揮作用,表現出人類朋友的行為,例如詢問並真正傾聽答案,或者只是傾聽並在適當的時候保留判斷。
人類如何體驗音訊信號?
與任何語言交流一樣,音訊資訊也使用語言和文字來傳達思想、情感和觀點。此外,音調、速度、音量和背景雜音等其他交流元素也會影響對資訊的整體感知。
從科學的角度來看,人耳基於兩個關鍵因素來感知音訊信號:頻率和聲壓級。聲壓級(SPL)以分貝(dBSPL)為單位,表示圍繞環境大氣壓振盪的聲壓幅度。100dBSPL 的聲壓級相當於割草機或直升機發出的巨大噪音。聲壓級範圍內的最低點(0dB)等效於 20µPa 的聲壓振盪,這代表具有最佳聽力的健康年輕人在 1kHz 頻率下的聽力閾值。所有與語言有關的人類聲音都屬於 100Hz 至 8kHz 的頻段。根據 ISO226:2023 標準,相應的人類聽力閾值如圖 1 所示。
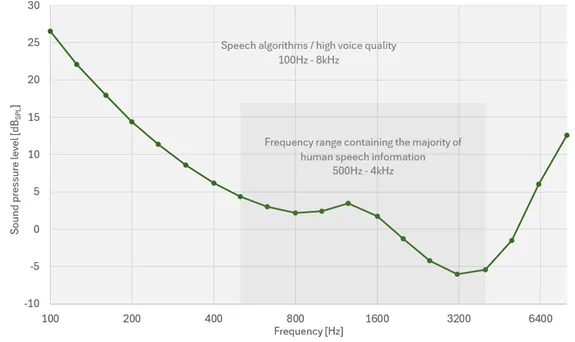
圖 1 聽力閾值。根據 ISO226:2023,人在重複試驗中做出 50% 正確檢測反應的聲級。
如圖 1 所示人耳對 500Hz 至 6kHz 範圍內的頻率特別敏感。這些頻率上的任何頻率平衡問題都會對聲音和樂器的感知品質產生重大影響。500Hz 至 4kHz 之間的頻率包含了人類語音中影響語音清晰度的大部分資訊。具體來說,2kHz 左右的頻率尤為重要。5kHz 至 10kHz 的頻率對音樂非常重要。這些頻率為聲音增添了“活力”和“亮度”。然而,這些頻率包含的語音資訊相對較少,只有噝聲,即“zhi”、“chi”和“shi”等詞開頭的嘶嘶聲。降低 6-8kHz 左右的噝聲會對語音清晰度產生不利影響。
我們大多數人都知道,人類的聽力閾值會隨著年齡的增長而下降,如圖 2 所示。
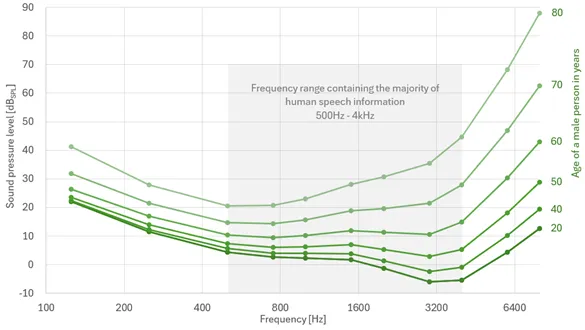
圖 2 該圖顯示了不同年齡段本體正常的男性在單聲道耳機聆聽條件下的聽閾衰減情況。請注意,女性也有類似的圖表,其聽力衰減程度隨年齡增長而略有降低(ISO7029:2017)。
值得注意的是,即使是輕度聽力損失(大多數人的聽力損失發生在 40 至 50 歲之間)也會對個人生活產生重大影響。例如,患有輕度聽力損失的人在嘈雜的環境中跟不上集體談話可能會遇到困難。此外,他們還可能錯過重要的聽覺提示,如警告信號或警報。
目前的音訊硬體是否足以滿足未來人工智慧的需要?
既然我們已經對人類如何感知音訊信號有了更好的瞭解,那麼讓我們重新審視一下最初的問題,即當前和未來的人工智慧需要什麼樣的音訊輸入品質,才能達到與人類無異的水準。
目前市場上的大多數消費類設備都使用 MEMS 麥克風記錄音訊信號。MEMS 麥克風 是人工智慧個人助理的主要音訊捕捉技術,使用人工智慧助理技術的設備目前已開始在市場上銷售。
MEMS 麥克風的錄音品質取決於其動態範圍 (dynamic range)。動態範圍的上限由聲學超載點 (AOP) 確定,它定義了麥克風在高聲壓級時的失真性能。麥克風的自雜訊確定了其動態範圍的下限。衡量麥克風自雜訊的方法是信噪比(SNR),它定義了麥克風的自雜訊與其捕獲的信號 (靈敏度) 之間的比率。不過,就我們的討論而言,信噪比有些不合適,因為信噪比的自雜訊使用了 A 計權(A-weighting),而 A 計權其實是基於人類感知音訊信號的能力來定義的。
如果音訊信號的預期接收者是人工智慧,則相關的麥克風的等效雜訊級 ENL(equivalent noise level)是衡量性能的更合適參數,因為它忽略了錄製聲音的人類感知因素。等效雜訊級 ENL 指的是在沒有外部聲源的情況下麥克風產生的信號。等效雜訊級 ENL 以分貝(dBSPL)為單位,表示與麥克風自雜訊相同電壓的聲壓級。
值得注意的是,無論後期採用何種聲音處理方法,低於等效雜訊級 ENL 的任何聲音資訊基本上都會丟失,無法恢復。因此,如果音訊鏈路中沒有其他元件在信號到達人工智慧演算法之前引入噪音,麥克風 ENL 就可以被視為人工智慧演算法的聽覺閾值。應該注意的是,這是一個高度簡化的假設,因為音訊鏈中通常還有許多其他元件,包括聲道、防水保護膜和音訊處理鏈路。
請參考圖 3 兩種MEMS 麥克風等效雜訊級 ENL 曲線與人類聽力閾值的直觀對比。
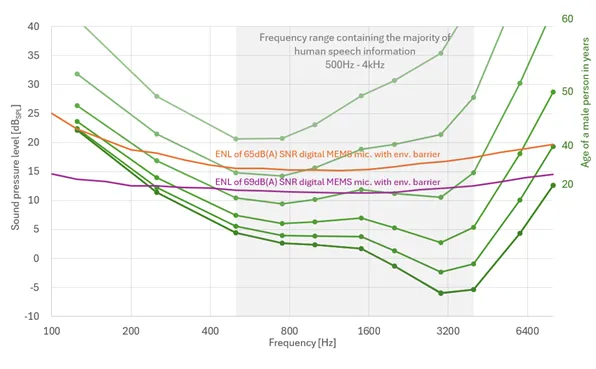
圖 3 中端和高端 MEMS 麥克風的 1/3 倍頻程等效雜訊級 ENL 與典型男性聽力閾值的比較
紅色線條的是信噪比為 65dB(A) 的麥克風的等效雜訊級 ENL 曲線,麥克風集成了防塵設計。相應的 MEMS 麥克風目前已用於多家供應商生產的多款高端智慧手機中。
下面的紫色線條表示英飛凌最新高端數位麥克風的等效雜訊級 ENL 曲線,該麥克風具有創新的防護設計,可實現防塵防水效果。這款麥克風代表了當前的技術水準,今年才在高端平板電腦上發佈。我們預計,到今年年底,性能相當的麥克風將出現在高端智慧手機上。值得注意的是,將麥克風的自雜訊降低 5-10dB 是一項重大成就,特別是考慮到聲壓是使用對數刻度來表示的。
雖然英飛凌在降低高端 MEMS 麥克風的自雜訊方面取得了顯著進展,但與人耳相比,麥克風在辨別低聲壓級的能力方面仍有很大差距。尤其是 2kHz 附近,對於確保人類聽眾獲得高水準的聲音清晰度至關重要。年輕人的聽覺能力與英飛凌最先進的麥克風之間的差距超過 12dBSPL。與目前高端手機中使用的麥克風相比,差距明顯更大,達到 17dBSPL。需要再次指出的是,這一評估僅考慮了 MEMS 麥克風的自雜訊,並未考慮音訊鏈中會進一步降低整體性能的額外噪音源。
目前 MEMS 麥克風技術的局限性在包含大部分人類語音資訊的頻率範圍(500Hz - 4kHz)內最為明顯。即使是市場上最先進的 MEMS 麥克風,其聲音理解能力也只能達到 60 歲老人的水準。根據現有資料,可以合理地預計,使用最新 MEMS 麥克風技術的人工智慧虛擬助手將出現與老年人類似的聽力障礙,特別是在需要在嘈雜環境中或遠距離跟讀對話的情況下。
總結與展望
人工智慧的飛速發展不僅不會減緩,反而會加速 MEMS 麥克風向更高信噪比發展的趨勢。雖然最新的 MEMS 麥克風還無法與人耳的音訊品質相媲美,但英飛凌在降低麥克風自雜訊方面取得的進展有利於現有和未來的人工智慧。進一步改進音訊鏈路將是增強人工智慧能力的關鍵,例如周圍環境分辨、語境理解、情感意識、說話者識別和多人對話記錄。有了更好的音訊輸入,人工智慧與人類的互動方式將能與人類之間的互動相匹配,甚至不相上下。
此外,人機交互水準的提高將促成新的基於人工智慧的用例和服務。例如,想像一下未來的微軟 Copilot,它不僅能總結團隊會議內容,還能提供對交談氛圍的整體評估。未來的人工智慧協助工具或許可以基於人類的語音和音訊,突出顯示重點或按照重要性進行排序。此外,還可以添加輔導功能,為用戶提供有用的建議,幫助他們更好地將未來的對話引向所需的方向。
試想一下,人工智慧可以對新的求職者進行第一輪面試,或者僅憑音訊就能識別說話者,其安全級別足以滿足網上購物的需要。
所有這些可能只是未來人工智慧的一小部分,未來人工智慧的聽力能力將達到或超過人類。憑藉我們的增強型 MEMS 麥克風解決方案,英飛凌很榮幸能夠參與這一激動人心的旅程。
了解更多MEMS完整內容,請掃碼下載白皮書-《英飛淩傳感選型手冊2024》

掃描二維碼, 關注英飛凌官方微信尋找更多應用或產品資訊
